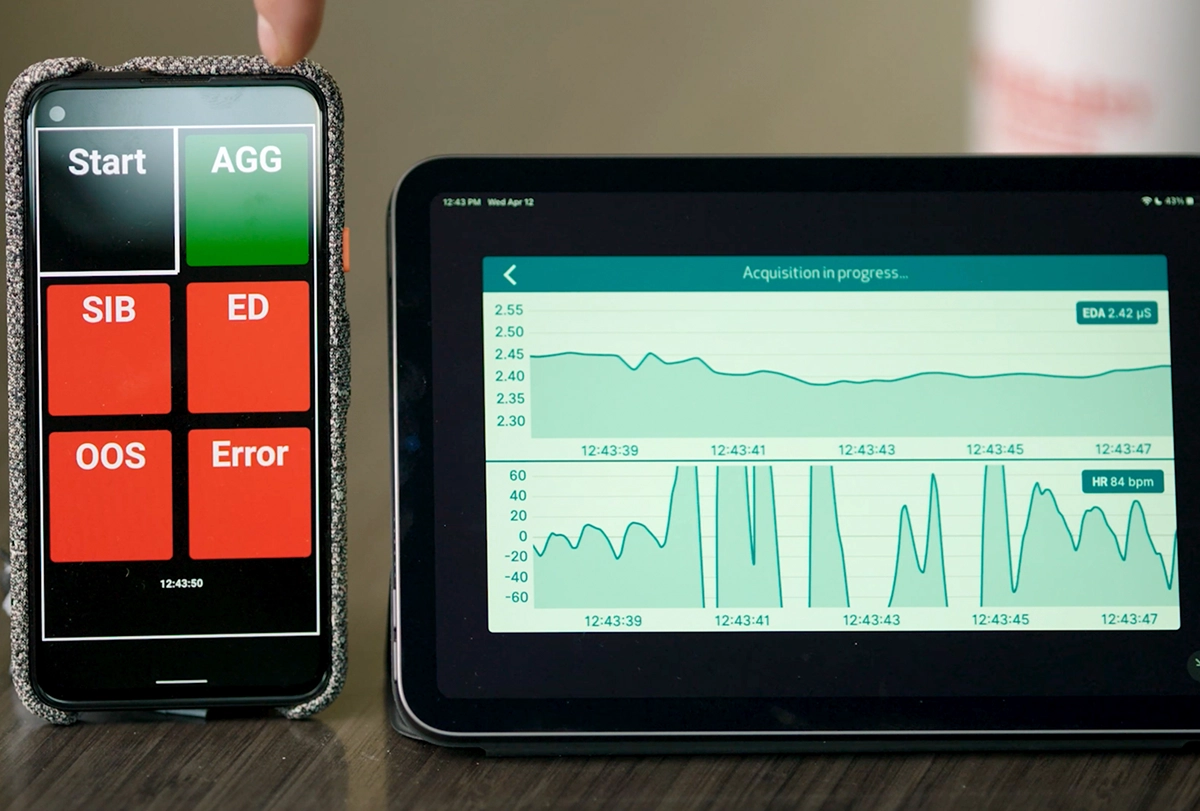
Wearable biosensors can forecast aggressive behavior in autistic people three minutes before an outburst, according to a study published in December in JAMA Network Open. That window, says lead investigator Matthew Goodwin, interdisciplinary professor at Northeastern University, “is enough time to do something.”
Within three minutes, for instance, caregivers might be able to intervene to calm a child with profound autism before they engage in behavior harmful to themselves or others.
Goodwin and his colleagues have been developing this technology for several years, but their latest paper reproduces and significantly expands on proof-of-concept findings they published in 2019, adding more participants, study sites and predicted behaviors.
To further advance the approach, the team is refining software and algorithms that support real-time phone notifications of impending aggressive behavior and designing studies to explore how people benefit from such alerts. They are also collaborating with the Marcus Autism Center to develop behavior management plans and targeted intervention strategies to complement these early warnings.
Many fundamental questions still need answers before these tools can reach families, Goodwin says. To help with that, he and his colleagues are sharing the data from their study on SFARI Base, including electrodermal activity, blood volume pulse and behavioral annotations for 69 participants over 497 hours of observation. (The Simons Foundation, The Transmitter’s parent organization, funds SFARI Base.) The dataset went live on 16 April 2024.
“There are a lot of people who are interested [in the research], and a subset probably have some knowledge they can bring to bear,” he says. “Now, with the dataset on SFARI Base, they can actually work with it.”
The Transmitter spoke with Goodwin about this decision and his hopes for collaborating with other experts.
The interview has been edited for length and clarity.
The Transmitter: Why share the dataset from this latest study?
Matthew Goodwin: Multiple reasons. One is scientific transparency. There’s a lot of attention—rightly so—on research that involves machine learning. There’s concern that these are black boxes, that we put too much faith in them, and that only certain groups can achieve certain results.
I’d like people to look at our methods and data. So in the JAMA paper, we published a supplement that details, step by step, everything somebody needs to know to understand how we segmented the data, preprocessed the data, derived our features, [etcetera]. I want people to know exactly what we did.
Then, once they know, I want to emphasize reproducibility. I want to see if other people reach the same results that we received—and that we’re not a unicorn.
The grand challenge I would like to give this community, if I could, is to increase our prediction time into the future with a higher level of predictive validity and increased positive predictive value. I really wanted to crowdsource data analysis with other scientists. I don’t want my team to be the only one working with this data. The problem is too important and complex.
TT: With data tied to 6,000-plus behavioral episodes from 69 autistic youth, there is a lot to investigate. What do you think people might learn?
MG: There are many questions that you could ask. For instance, are there other features that could be hand-crafted to put into the models that would increase prediction length? Or increase accuracy?
And there are many questions beyond prediction. All four of the participating sites are part of the Autism Inpatient Collection, so the participants in our study all have SFARI global unique identifiers. If someone has permission to access this dataset, they can then ask about differences as a function of age, sex and verbal ability, for example.
Blood draws were also done for participants [and those data will be available in the coming months on SFARI Base], meaning you can explore different genetic profiles as well. There’s a lot of interest in connections between underlying genetic differences and behavioral manifestations.
TT: In other words, autism researchers, epidemiologists and geneticists might find something interesting here. Are there other experts you hope will explore this dataset?
MG: There are people with knowledge that I don’t have—in applied math, physics and machine learning—who could bring new insights. Essentially, we have provided time-to-event phenomena. There are people in econometrics and engineering who model airplanes taking off and landing, the effects of traffic, and the stock market with very sophisticated mathematical models. These people are not thinking about autism and aggression, but their mathematical methods are well suited to the challenge.
They can think of the data from our study like a multivariate time series and model the time to event. You don’t have to know anything about autism, physiology or aggression to do that.
I’d like to open a conversation because I don’t know who those people are now. I don’t know where they are. I don’t know how to find them. I don’t know how to entice them to work with me. This could be a way to do that.