Eric Schadt is Mount Sinai Professor in Predictive Health and Computational Biology at the Icahn School of Medicine in New York City. He is also founder and chief executive officer of the predictive health company Sema4.

Eric Schadt
Professor
Icahn School of Medicine at Mount Sinai
From this contributor

Counseling can ease shock of unexpected genetic results
The best way to deliver surprises from genetic findings is to provide adequate information and counseling alongside the results.
Counseling can ease shock of unexpected genetic results
By
Eric Schadt
23 October 2018 | 6 min read
Explore more from The Transmitter

Remembering Annette Dolphin, who helped explain gabapentin’s effects
The "intuitive" neuropharmacologist pushed against the status quo.
Remembering Annette Dolphin, who helped explain gabapentin’s effects
The "intuitive" neuropharmacologist pushed against the status quo.
By
Michael Eisenstein
13 March 2026 | 7 min read
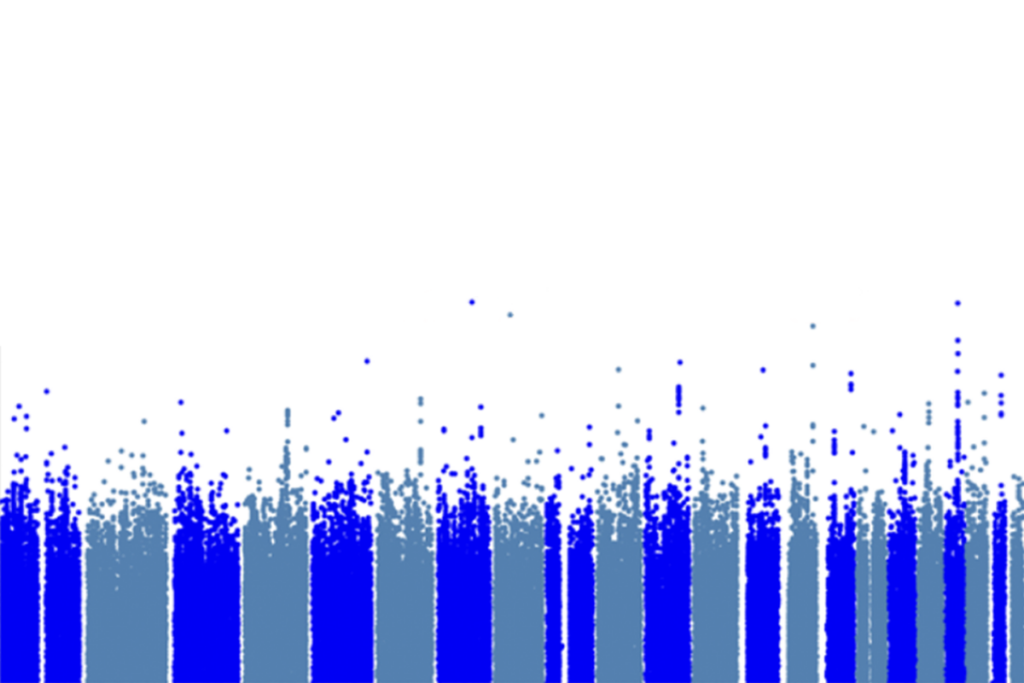
Revised statistical bar extracts less-common variants from autism genetics studies
Adjusting genetic analyses could help plug autism’s heritability gap, according to a new preprint.
Revised statistical bar extracts less-common variants from autism genetics studies
Adjusting genetic analyses could help plug autism’s heritability gap, according to a new preprint.
By
Holly Barker
12 March 2026 | 4 min read
Tom Griffiths describes how neural networks, logic and probability theory together explain cognition
In his new book, “The Laws of Thought,” Griffiths shows how these three pillars of study complement one another and together form a solid foundation to eventually explain all of our cognition, from brain to mind.
Tom Griffiths describes how neural networks, logic and probability theory together explain cognition
In his new book, “The Laws of Thought,” Griffiths shows how these three pillars of study complement one another and together form a solid foundation to eventually explain all of our cognition, from brain to mind.
By
Paul Middlebrooks
11 March 2026 | 100 min listen