Khara Ramos is director of the Neuroethics Program, and health scientist administrator in the Office of Scientific Liaison, at the National Institute of Neurological Disorders and Stroke.

Khara Ramos
Director, Neuroethics Program
National Institute of Neurological Disorders and Stroke
From this contributor
U.S. initiative grapples with ethical questions on brain research
Khara Ramos explains how the Brain Initiative incorporates the emerging field of ‘neuroethics’ into the research it funds.
U.S. initiative grapples with ethical questions on brain research
By
Emily Anthes
19 October 2019 | 4 min read
Explore more from The Transmitter

How thirteen-lined ground squirrels illuminate retinal development
In most mammalian retinas, rods outnumber cones. But that ratio is flipped in ground squirrels, a quirk that helps Seth Blackshaw explore how retinal cells develop their identities.
How thirteen-lined ground squirrels illuminate retinal development
In most mammalian retinas, rods outnumber cones. But that ratio is flipped in ground squirrels, a quirk that helps Seth Blackshaw explore how retinal cells develop their identities.
By
Sarah Thau
31 July 2026 | 5 min read

Highlights from the first-ever Neural Genetics and Epigenetics Gordon Research Conference
The meeting’s organizers recap the science to watch.
Highlights from the first-ever Neural Genetics and Epigenetics Gordon Research Conference
The meeting’s organizers recap the science to watch.
By
Francisco J. Rivera Rosario
30 July 2026 | 4 min read
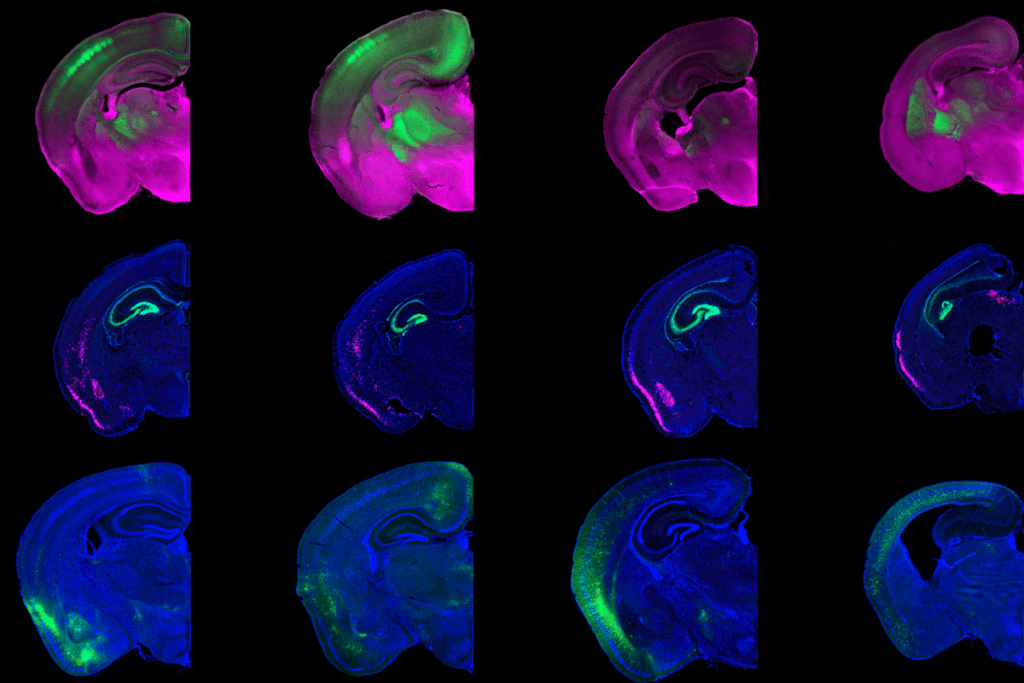
Cortical territories compete in developmental space race
Sensory and association regions are established through a reciprocal process, according to a new model of cortical development.
Cortical territories compete in developmental space race
Sensory and association regions are established through a reciprocal process, according to a new model of cortical development.
By
Holly Barker
30 July 2026 | 5 min read