Valerie Bolivar is director of the Mouse Behavioral Phenotype Analysis Core in the Division of Genetics at the New York State Department of Health’s Wadsworth Center.

Valerie Bolivar
Research scientist
New York State Department of Health
From this contributor

How variability among mouse strains can aid autism research
Researchers can convert the distinct genetic backgrounds of lab mice from a problem to an advantage, exploiting the differences to advance our understanding of autism.
How variability among mouse strains can aid autism research
By
Valerie Bolivar
21 March 2018 | 4 min read
Explore more from The Transmitter
Romain Brette reveals fundamental flaws in commonly assumed neuroscience concepts
His new book, “The Brain, In Theory,” offers alternatives to many of the computer science frameworks currently driving theoretical neuroscience.
Romain Brette reveals fundamental flaws in commonly assumed neuroscience concepts
His new book, “The Brain, In Theory,” offers alternatives to many of the computer science frameworks currently driving theoretical neuroscience.
By
Paul Middlebrooks
8 April 2026 | 131 min listen
Arboreal deer mice reveal neural roots of dexterity
The rodents offered researchers an opportunity to link genetically driven changes in corticospinal abundance and morphology to climbing cachet.
Arboreal deer mice reveal neural roots of dexterity
The rodents offered researchers an opportunity to link genetically driven changes in corticospinal abundance and morphology to climbing cachet.
By
Siddhant Pusdekar
8 April 2026 | 0 min watch
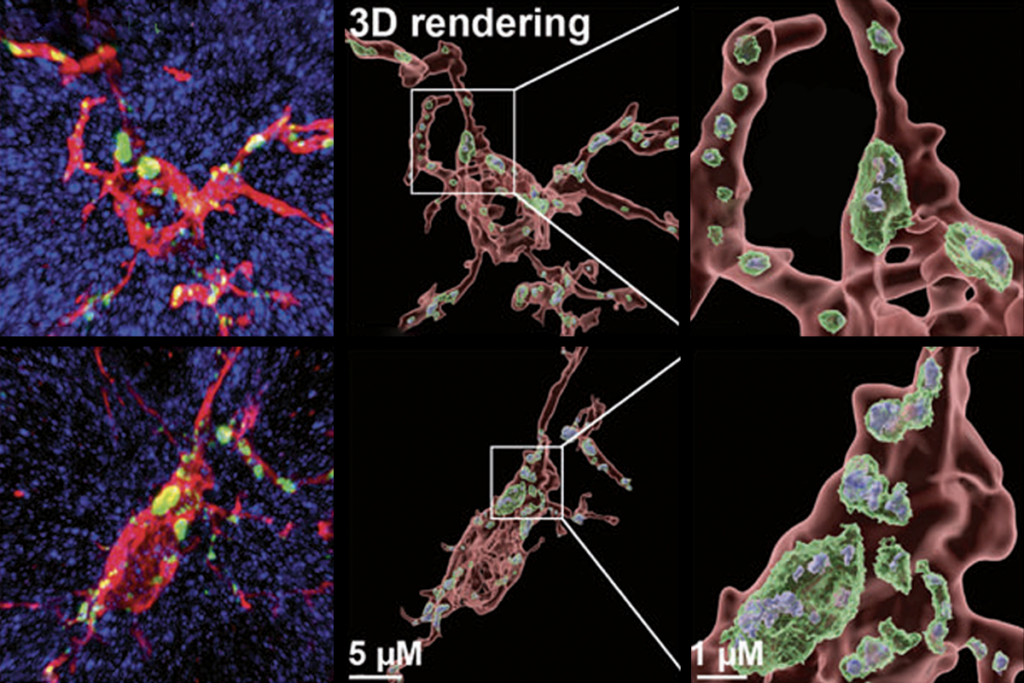
Single-gene systems-level effects, and more
Here is a roundup of autism-related news and research spotted around the web for the week of 6 April.
Single-gene systems-level effects, and more
Here is a roundup of autism-related news and research spotted around the web for the week of 6 April.
By
Jill Adams
7 April 2026 | 2 min read