Listen to this story:
0:00
/

Simple math suggests that small groups of scientists can significantly bias peer review.
Despite the massive rise in preprints over the past few years, peer review at journals is still widely held as the gold standard for assessing the validity of results in neuroscience.
Even if we acknowledge that mistakes occasionally fall through the cracks, scientists generally assume that peer review quickly self-corrects the literature; the idea is that over the course of multiple papers, enough people vet the assumptions, approaches and ways of thinking to ensure that they are valid.
But what happens if multiple scientists share the same misconception? It’s clear that individual wrong ideas, such as the claim that vaccines can cause autism, can spread in society through failures in journalism or social media, even after science has corrected the record. But are there mechanisms by which mistakes can similarly propagate through peer-reviewed literature before failed replications or retractions catch up with them?
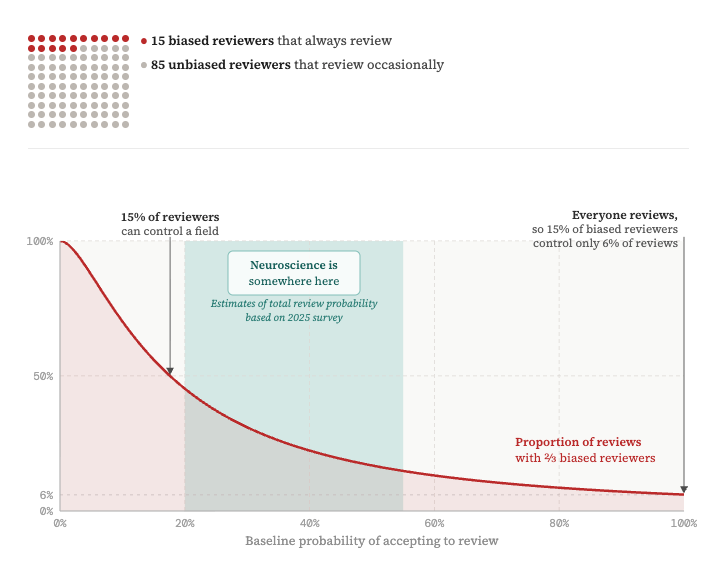
To get an intuition for this problem, let’s examine how many people need to make the same mistake—deciding to ignore an alternative interpretation of a result or using an invalid experimental approach, for example—for that view to be reflected in peer-reviewed papers. Similarly, how big of a group holding a strong opinion can keep conflicting points of view out of the literature? A simple back-of the envelope calculation, which I detail below, shows that this number is surprisingly small: Because of the low rates at which neuroscientists agree to review manuscripts, it is possible for small groups of labs—as few as 15 to 20 scientists—to end up in review “filter bubbles” that fail to properly vet results.
A
For a paper to be peer reviewed, an editor first must decide it is worthy of their journal and believe they can find reviewers. If candidates decline, the editor keeps reaching out until they eventually find three (or in some cases, two or four) reviewers. In neuroscience, reviewer pools can be small: Subfield conferences often fit the majority of a field into small lecture halls, and in many cases it seems realistic to put the number of potential reviewers for a paper at well below 50.
The problem with current peer review, however, is not that fields are small but that the number of scientists who actively review is much smaller: From a survey we conducted in 2024 and 2025 of editors at major neuroscience journals, we found that depending on the subfield, journal and editor, only 20 to 50 percent of review requests are accepted.
This low review rate gives scientists who do agree to review specific papers an outsized influence. This pool could include reviewers with particularly strong opinions on some topic or those in active disagreement with the authors. Papers bounce around the reviewer pool until they hit one of these few always-reviewing scientists, giving that reviewer significantly more influence than the average, rarely reviewing scientist. This effect risks funneling reviews into a narrow category of reviewer.
To estimate the outcome of such imbalance, we can calculate the probability that any accepted review request comes from a biased group that always agrees to review. (This is just an application of Bayes theorem; see appendix for details.)
To explore how the baseline review probability and percentage of biased reviewers influence the likelihood of biased review, check out this interactive simulation:
You are submitting a paper (📄). Sadly, most of your colleagues (😐) are not interested in reviewing many papers, but a subset of very opinionated reviewers (😈) will always review.
In your field of ~100 people, there are 15 such reviewers.
Let’s see how likely it is for 2 out of 3 reviewers to be from that group.
Reviewers for this paper:
This effect is not subtle: If we plug reasonable numbers into our formula—say most scientists accept only 20 percent of review requests—then in order to form the majority in half of all reviews, an always-reviewing group needs to make up just 16 percent of the field. Review rates of 20 percent therefore threaten the robustness of peer review; small groups of scientists can deliberately or unwittingly end up in review filter bubbles that lack proper vetting. Should this mechanism lead to groups of faulty papers that are not properly reviewed, science still self-corrects, but only through the slow and costly process of failed replications. To avoid this dynamic, we should operate with a review rate of 50 percent or higher.
Low review participation also explains the common belief that reviews are more polarized than other interactions among scientists: It is likely that cranky reviewer No. 3 agreed to review your paper only after multiple less opinionated colleagues decided they didn’t feel strongly enough about the work to spend time reviewing it.
O
However, many consumers of science—be it scientists reading work outside their field, hiring and funding committees, policymakers or the public—lack the resources required to evaluate the science; they need secondary signals of impact and robustness. So how do we increase the breadth of evaluations, making peer review reliable enough to serve this function?
One proposal to increase the reviewer pool is to pay reviewers. The fact that scientists collectively pay publishing companies as much as $1 billion per year in publishing fees suggests that ample funding is available to be redirected to such efforts, even in an uncertain science funding climate.
Journals have also experimented with novel forms of review, such as the collaborative reviews at eLife, eNeuro or Frontiers journals, with the goal of improving review quality and reducing the burden on individual reviewers.
Another approach is post-publication review. Lab meetings and journal clubs frequently discuss preprints, providing large reserves of untapped reviewer time. Such evaluations could in their sum be of higher quality than a traditional review: They are more diverse, incentivized by a desire to understand or replicate the work, and less affected by the conflicts of interest inherent in accept/reject decisions. Surfacing this collective expertise for a broader audience could improve the current system, if we manage to avoid the dangers of an unmoderated free-for-all, which could suffer from low participation or manipulation by malicious actors just as other online forums can. So far, despite increasing interest, efforts to build such systems, such as PubPeer, Review Commons, PREreview and F1000, have failed to replace the traditional one-time review at journals.
Recently, there have been calls to remedy this issue using artificial-intelligence methods. Barring the discovery of actual artificial general intelligence, this is a dangerous idea. Though large language models can likely help summarize research, check consistency with other papers or act as search engines to suggest related work or reviewers, they lack precisely the thing that makes peer review work: the human ability to handle unforeseen new data and to reason through complicated arguments to arrive at conclusions that can overturn decades of prior thinking. Asking LLMs, which lack world models and instead scaffold off existing data, to review would feed faulty conclusions back into training data and pollute the literature with false claims.
Peer review is a scarce and precious resource. Broad peer review is crucial for a healthy scientific literature, and without it science only self-corrects on a slower timescale, such as through failed replications. However, neuroscientists currently turn down review requests far too often. We need to reverse this trend by bolstering participation, making peer review more efficient where possible, and supplementing it with additional evaluation mechanisms.
Credit: Jakob Voigts