Aled Edwards is professor of molecular genetics and medical biophysics at the University of Toronto in Canada and founder and director of the Structural Genomics Consortium.

Aled Edwards
Professor of molecular genetics and medical biophysics
University of Toronto
From this contributor

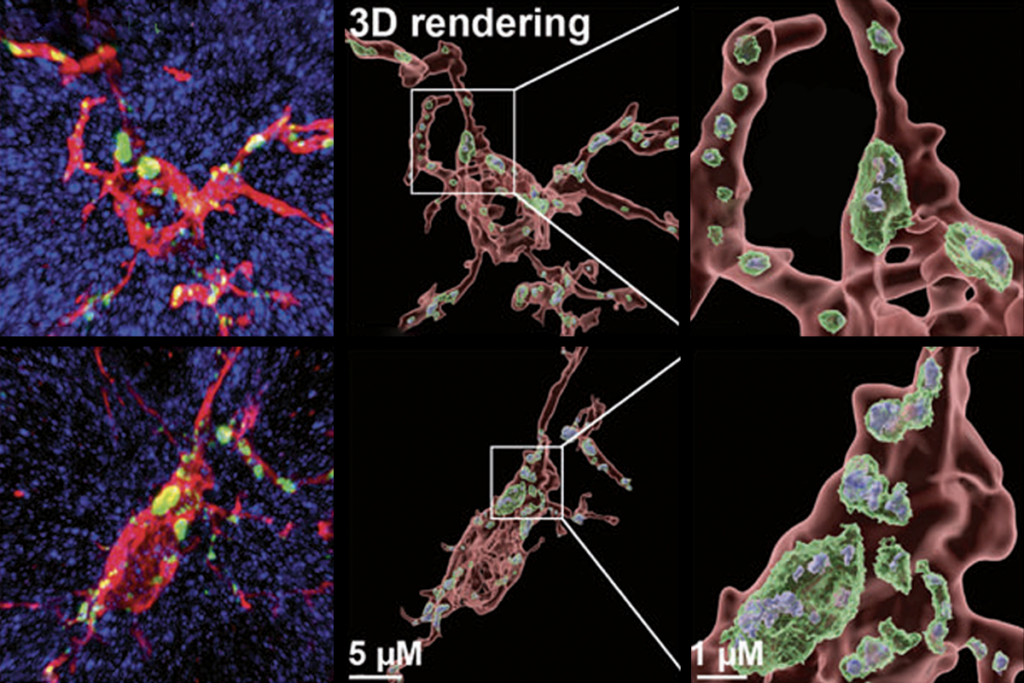
We found a major flaw in a scientific reagent used in thousands of neuroscience experiments — and we’re trying to fix it.
As part of that ambition, we launched a public-private partnership to systematically evaluate antibodies used to study neurological disease, and we plan to make all the data freely available.
Explore more from The Transmitter
Romain Brette reveals fundamental flaws in commonly assumed neuroscience concepts
His new book, “The Brain, In Theory,” offers alternatives to many of the computer science frameworks currently driving theoretical neuroscience.
Romain Brette reveals fundamental flaws in commonly assumed neuroscience concepts
His new book, “The Brain, In Theory,” offers alternatives to many of the computer science frameworks currently driving theoretical neuroscience.
By
Paul Middlebrooks
8 April 2026 | 131 min listen
Arboreal deer mice reveal neural roots of dexterity
The rodents offered researchers an opportunity to link genetically driven changes in corticospinal abundance and morphology to climbing cachet.
Arboreal deer mice reveal neural roots of dexterity
The rodents offered researchers an opportunity to link genetically driven changes in corticospinal abundance and morphology to climbing cachet.
By
Siddhant Pusdekar
8 April 2026 | 0 min watch
Single-gene systems-level effects, and more
Here is a roundup of autism-related news and research spotted around the web for the week of 6 April.
Single-gene systems-level effects, and more
Here is a roundup of autism-related news and research spotted around the web for the week of 6 April.
By
Jill Adams
7 April 2026 | 2 min read