Listen to this story:
0:00
/
Movement-sensing neurons that target the striatum influence a mouse’s choice of action by favoring routine.
Dopaminergic neurons that target the tail of the striatum catalog recurring behaviors to streamline decision-making, according to a new mouse study.
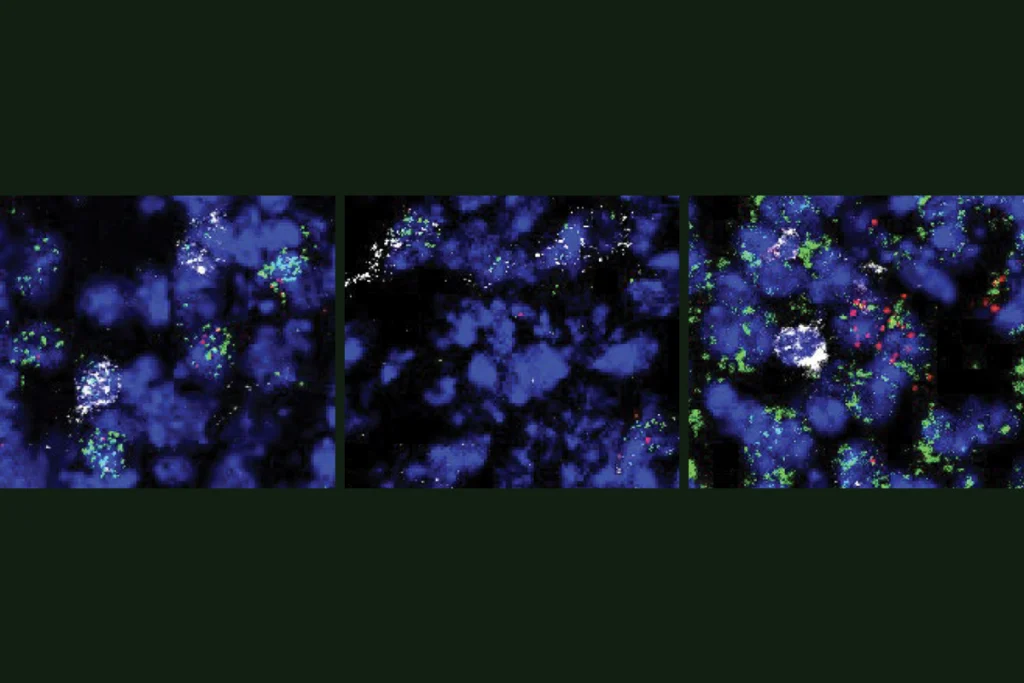
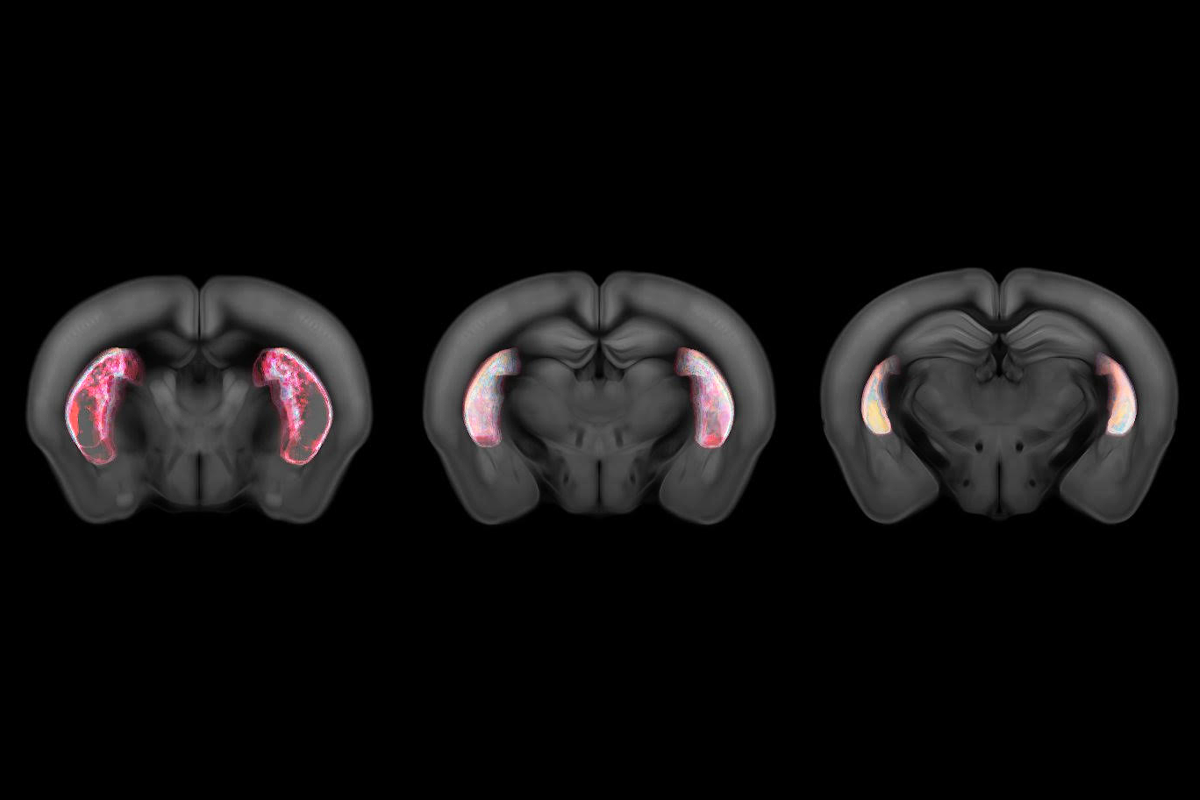
The cells respond to movement and release dopamine when mice learn to associate specific actions with auditory cues—such as turning right after a shrill sound or left in response to a low-pitch note, the study shows. Damage to the tail of the striatum impedes the animals’ learning, the findings suggest.
Initially, animals make their choice based on which option yields the most rewarding outcome. But over time, the brain decides based on previous actions, regardless of whether the outcome has since changed, says co-principal investigator on the study, Marcus Stephenson-Jones, group leader at the Sainsbury Wellcome Centre for Neural Circuits and Behaviour. This non-value-based approach automates decision-making and frees up cognitive resources for other tasks, he adds.
The work, which was published last month in Nature, could explain why habits are difficult to break, even when they are no longer pleasurable, says Ian Ballard, assistant professor of psychology at the University of California, Riverside, who was not involved in the study. “It explains a lot of the data we’ve been seeing in psych research for a long time, that people tend to repeat past actions regardless of the outcome,” he says.
Dopamine neurons in the midbrain signal the value of possible outcomes when animals make decisions, according to studies dating back to the late 1990s. Known as reward prediction error (RPE), dopaminergic activity reflects whether an outcome is better or worse than expected. But the classic RPE theory doesn’t always mirror experimental findings: Dopaminergic neurons respond to diverse stimuli, from simple movements to perceived threats.
A newer theory—backed up by a computational model—suggests that movement-related dopamine neurons can reinforce habits in a value-free way. This second pathway, called action prediction error (APE) represents the discrepancy between an executed action and its predicted occurrence. APE updates whenever an action reoccurs, making the behavior more likely.
According to this theory, the size of the APE signal weakens as an animal learns to predict the action they’ll take. Indeed, dopamine release diminished in mice engineered to express a fluorescent dopamine receptor when they correctly linked a movement direction with a sound, the new study found. And when the researchers adjusted the size of the reward—by giving the animals a bigger drink of water—dopamine signals from the tail of the striatum remained the same.
“The study supports the key predictions of the [computational] model,” says Rafal Bogacz, professor of computational neuroscience at the University of Oxford, who developed the model but wasn’t involved in the new study. The day he first heard of the study’s findings “was one of the most satisfying days of my scientific career,” he says.
B
ut key features of prediction errors remain unexplored in the new study, says Nathaniel Daw, professor of computational and theoretical neuroscience at Princeton University, who did not take part in the work.For example, monkeys that have learned to associate a juice reward with a flash of light show a strong RPE signal in response to both the cue and the reward. And when they are exposed to the light cue without the juice, that dopamine signal is inhibited, according to a seminal 1997 study.
Showing the same negative signal when a predicted action is withheld would make the new work more conclusive, Daw says.
It’s unclear, however, whether APE signals would disappear when movement is suppressed, Stephenson-Jones says. “Actively withholding a response often comes with muscle contraction and so even this may still elicit a positive APE. Even if we were able to show this, I think it would be quite a contrived situation that may never, or at least rarely, occur,” he adds.
So far, it’s also unclear where threat fits into the dual learning model. Dopamine neurons that respond to threat also target the tail of the striatum, and an independent 2018 study proposed that this activity encodes a threat prediction error (TPE).
Stephenson-Jones says he and his colleagues are planning to investigate how TPE and APE work together in the same brain circuit. Future experiments may also uncover whether movement-related dopamine neurons targeting other parts of the striatum, such as the dorsolateral region, also encode APE. If so, the dual model might apply to more complex behaviors, such as learning an instrument, Stephenson-Jones says.