Listen to this story:
0:00
/

Eight researchers explain how they are using large language models to analyze the literature, brainstorm hypotheses and interact with complex datasets.
Over the past few years, large language models (LLMs) have grown rapidly in both scale and skill. They are better at complex reasoning, can follow scientific prompts, and now process not just text but figures and code as well. Scientists have quickly co-opted these strengths, building LLMs into their workflows; they are using these tools to analyze the literature, brainstorm hypotheses, query databases, interact with complex datasets and investigate new results. Read on as eight neuroscientists describe how they are employing these tools in their labs.
Responses have been lightly edited for length and clarity.
In our lab, we’re using the same core technology behind LLMs to tackle a completely different kind of language: the language of cellular organization, measured by spatial genomics experiments. We asked a simple question: Can an artificial-intelligence model interpret cells based on their surrounding cellular context, much like language models interpret words within a sentence? It turns out the answer is yes.
We developed a model called CellTransformer that learns to predict a cell’s molecular features based on its “cellular neighborhood,” the small community of cells immediately surrounding it. We trained the model on a massive spatial genomics dataset, collected by our collaborators at the Allen Institute, in a self-supervised way; the AI model examines a cellular neighborhood, leaving out one cell’s molecular identity, and then tries to predict the hidden cell’s identity based on its neighbors. By repeating this process millions of times, it learns the fundamental rules of how different cells are arranged together. This approach is different from previous brain-mapping efforts that aimed to define different cell types in the brain. Instead, our method figures out how those cell types are assembled into larger, functional regions. The model effectively learns the rules of neuroanatomy from the ground up, without any human guidance. The result is a new, ultra-high-resolution map of the brain, created in an entirely data-driven way. We were thrilled to see that CellTransformer reproduced the known, large-scale regions of the brain with incredible accuracy and also discovered many previously un-cataloged, finer-grained subregions.
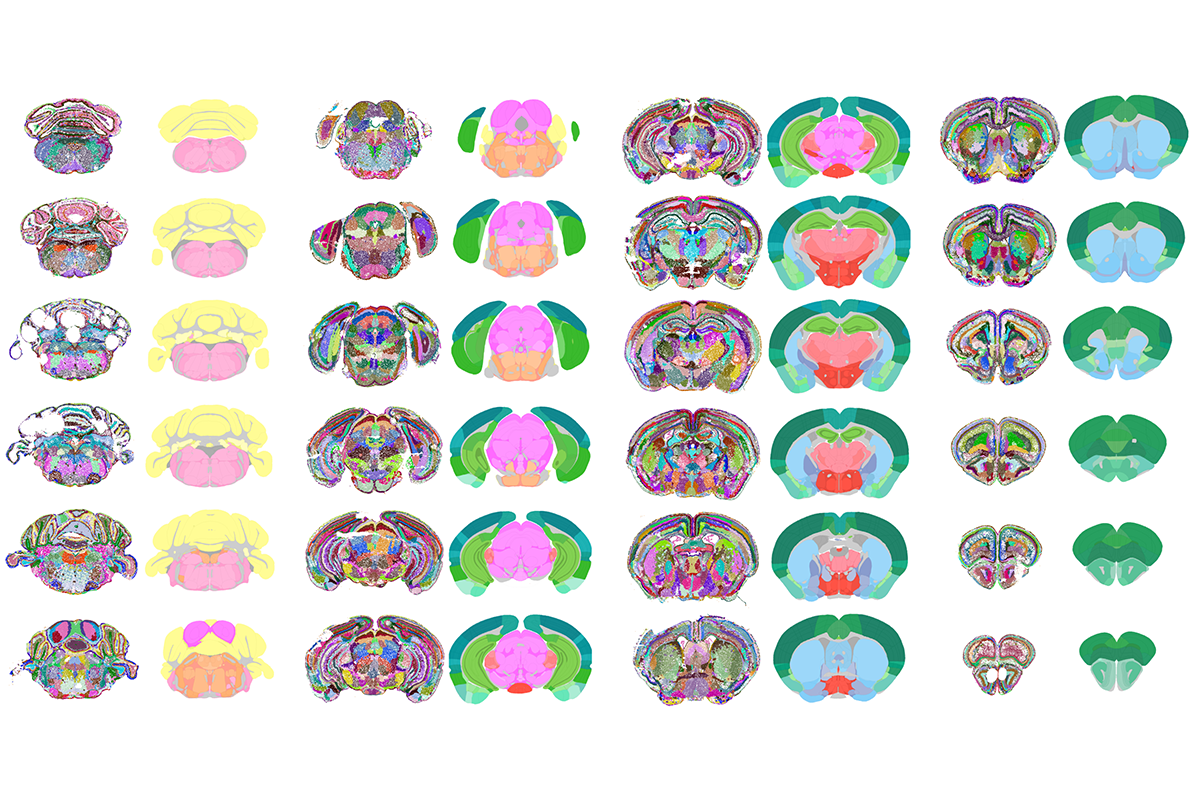
This is really exciting because, for decades, preclinical research has relied on what are essentially hand-drawn maps of the brain, which have been biased by historical interest in different areas of the brain. Our AI-generated map offers a more detailed and unbiased representation, enabling scientists to associate disease states or drug actions with highly specific, cellularly defined regions in the brain, and it can be readily applied to newer datasets as they emerge.
What’s perhaps most exciting is that the CellTransformer framework isn’t just for neuroscience. We designed it as a powerful, tissue-agnostic tool that can be applied to any organ system in which large-scale spatial transcriptomics data are available. This provides not just a new brain map but a foundational solution for creating high-resolution cellular maps for virtually any area of biology. Ultimately, we see this as a scalable platform that will pave the way for a deeper, data-driven understanding of tissue organization across countless different species and disease states.
LLMs have greatly transformed the way I work and now constitute an integral part of my daily research routine. As a non-native English speaker, I previously struggled to phrase ideas clearly—whether hitting the right tone in an email or refining a thoughtful paper review. Now I use LLMs to polish my drafts, check grammar and adjust tone, making writing much more accessible for researchers like me who aren’t native speakers. Beyond writing, I rely on LLMs for coding tasks, particularly for generating small snippets for data plotting or debugging. The interactive nature of these tools helps me think through problems more effectively than working alone. I also find myself bouncing ideas back and forth with LLMs—whether brainstorming analysis approaches or thinking through how to structure a paper I am writing.
My research is highly collaborative, involving frequent meetings that we transcribe and then process with LLMs to generate organized summaries with clear action items—a huge time-saver. More recently, we have begun using advanced models such as VLMs (vision-language models) as powerful assistants for scientists. This technology allows researchers to perform analyses traditionally requiring human interpretation, but at a scale and speed that would otherwise be unfeasible. For example, our research involves understanding how neurons in the visual cortex respond to different images, and we can now use LLMs to automatically describe what these images have in common—something that would take researchers much longer to do manually.
Although I use these tools regularly, I maintain a critical perspective on their outputs. If one keeps a critical perspective on the output and remains aware of limitations such as hallucinations, I believe AI tools, such as LLMs, have enormous potential to revolutionize the way we work. (And yes, I used an LLM to help polish this very text!)
The BrainGPT.org project investigated whether LLMs trained on neuroscience literature could outperform human experts in predicting experimental outcomes across neuroscience subfields. An international team from 11 countries developed BrainBench, a benchmark based on Journal of Neuroscience abstracts, that tested both human experts and LLMs on distinguishing between actual and subtly altered research results.
The key finding was that LLMs demonstrated superhuman ability to predict experimental outcomes, with well-calibrated confidence levels—meaning that higher confidence correlated with greater accuracy. This groundbreaking research suggests LLMs could fundamentally change how neuroscience research is conducted. Two major implications emerged. First, because both LLMs and human experts show calibrated confidence, hybrid teams combining humans and AI could make more accurate predictions than either alone. Second, these systems could accelerate scientific discovery by leveraging LLMs’ unique capabilities.
A compelling example involves Michael Schwarzschild from Harvard Medical School and Massachusetts General Hospital, who discovered a potential Parkinson’s disease biomarker, only to later find that studies from the 1980s and 1990s had hinted at similar findings. When tested, BrainGPT’s LLMs correctly identified this innovative result as most likely, demonstrating their ability to uncover overlooked research and connect disparate scientific literature.
The team is now collaborating with AE Studio to develop open-source tools that will help scientists across disciplines harness these predictive capabilities. These tools aim to accelerate discovery by anticipating study outcomes and assessing the replication likelihood of past research.
Scientists, AI researchers and software developers can sign up to receive project updates or contribute to the effort. The team also seeks resources to host these tools, ensuring free and accessible community access. Those interested can get in touch with the team leads, Xiaoliang Luo (EmpiriQaL.ai) and me (Bradley Love, Los Alamos National Laboratory). This initiative represents a significant step toward AI-enhanced scientific research, potentially transforming how discoveries are made and validated across multiple scientific fields.
We’re using LLMs to make it easier for neuroscientists to reuse complex datasets from the DANDI (Distributed Archives for Neurophysiology Data) Archive. DANDI hosts hundreds of neurophysiology datasets that contain recordings of brain activity collected using techniques such as electrophysiology and calcium imaging, together with behavioral and stimulus data. These datasets are rich with potential for new discoveries, but it can be difficult to know where to start if you didn’t collect the data yourself. Our team built a system that uses LLMs to do some of that heavy lifting. First, an AI agent explores a dataset: It autonomously loads pieces of data from the remote files, runs exploration scripts, and generates and inspects visualizations to understand the data. Then, a second model uses the information gathered to write a Python notebook that introduces the dataset, showing how to get started loading, plotting and analyzing the data. After review by a human for accuracy, that notebook is made available online alongside the datasets. The goal is to help scientists go from “this looks interesting” to “I can work with this” in a matter of minutes. It’s a step toward making public neuroscience data more approachable and reusable.
When using LLMs, it’s important to be aware of the potential misleading information they can generate. I also started this project to test the LLMs to see if they would succumb to some common statistical pitfalls and risk reporting spurious findings. Presumably, as models get smarter, this will become less of an issue.
Disclosure: The Simons Foundation is the parent organization of both The Transmitter and the Flatiron Institute.
Frontotemporal degeneration (FTD) is a form of dementia that affects the brain’s frontal and temporal regions and impairs speech, decision-making and motor functions. Despite being the most common dementia in people under age 60, its molecular basis remains poorly understood. Our project, led by Ph.D. student Louisa Cornelis in collaboration with the Geometric Intelligence Lab at the University of California, Santa Barbara and the Memory and Aging Center at the University of California, San Francisco (including Guillermo Bernárdez Gil, Rowan Saloner, Kaitlin Casaletto and myself), tackles this gap using explainable graph neural networks (GNNs) on large-scale proteomics data from FTD patients. Our models predict future cognitive decline by detecting early molecular signs, sometimes before symptoms appear, to forecast how the disease will affect a patient’s life. We then apply LLM-augmented explainability techniques to identify the top proteins driving the model’s predictions to highlight molecular patterns that may underpin FTD.
We integrate LLMs into our explainability pipeline. After identifying the top 10 predictive proteins, a custom AI queries PubMed and summarizes relevant papers to answer questions such as: What are these proteins’ known functions? Which have known links to neurodegeneration, such as in Alzheimer’s or Parkinson’s disease research, or show up in animal studies? Which may be novel? Early tests already yield promising leads—for instance, surfacing papers between GNN-identified proteins and other neurodegenerative diseases, even without prior known FTD associations. Our team verifies all references. We have found that the automated search enriches interpretation and discussions, guiding our selection of proteins for future lab testing.
The approach does have limitations. The LLMs may introduce errors by hallucinating: citing nonexistent papers or non-peer-reviewed studies. To reduce this risk, we limit the LLM’s role to summarizing results from automated PubMed searches, with all outputs manually reviewed by our team. Even though the AI may still misinterpret findings or miss key literature, the tool remains valuable for hypothesis generation. We plan to formally evaluate its accuracy by tracking the ratio of valid to incorrect outputs through expert review on a large set of queries.
We use LLMs to overcome a challenge in biology and neuroscience: the sheer volume of research being published. Our project, MetaBeeAI, focuses on understanding how stressors, such as pesticides, affect insect brains and behavior. But the core issue is universal: Researchers can’t keep up with the literature. MetaBeeAI uses LLMs to read thousands of papers, identify relevant findings and extract structured data—including experimental designs, brain regions affected and behavioral outcomes—in a form that can be immediately incorporated into meta-analyses or computational models.
Crucially, this is not a “black box” system. We’ve designed MetaBeeAI as an expert-in-the-loop pipeline, in which researchers can verify outputs at every stage, correct errors and provide feedback that improves both the prompting and the fine-tuning of the LLMs over time. This makes the process transparent, auditable and adaptable to the needs of different domains. We’re also building a benchmarking dataset curated by domain experts, which helps evaluate LLM performance on real biological literature and pushes the models to become better readers of science.
Our ultimate goal is to make this tool available to researchers across neuroscience and biology, helping them extract critical findings, synthesize evidence and accelerate discovery.
In addition to the more standard uses of LLMs for writing and coding support, we use them as predictive models of brain processing. We recently found that the internal representations of GPT-type models—the same model family that powers tools such as ChatGPT—are surprisingly similar to the representations inside the human language network. When we present the same text to humans and to these models, we see a striking alignment between the two systems: The models’ internal activations predict both patterns of neural activity in the brain and behavioral responses such as reading times.
This alignment is strong enough that we can now use LLMs to choose sentences that reliably increase or decrease activity in specific parts of the human language system. I find this super exciting because it opens up possibilities for noninvasive modulation of brain activity purely via perceptual input rather than invasive procedures.
Inspired by these findings, we are also investigating LLMs as a “species” of interest: Using functional localizers from neuroscience on various models, we discovered that only a relatively small subset of an LLM’s components is devoted to core language processing, meaning that a large proportion is used for auxiliary tasks. This again mirrors how the human language network is distinct from broader systems for reasoning and world knowledge.
We are finding a lot of value in this bidirectional exchange: using AI models to understand the brain and neuroscience tools to dissect the models. And we see a growing synergy that I believe will lead to better and better models of the brain.
Computational models play an important role in neuroscience, combining abstract descriptions of neural processes with quantitative predictions that can be tested on data. Traditionally, implementing such models has been exclusively within the purview of humans: specifically, extremely expert human researchers with specialized knowledge of neuroscience and modeling. However, LLMs can now write executable code as well, opening the door to automatically generated computational models. Though LLM-generated code still trails that of skilled programmers, it can be produced quickly and at scale. Methods such as AlphaEvolve leverage this by generating and refining code within an optimization loop to discover programs that maximize some score. On our team, we are using this for data-driven computational model discovery, optimizing LLM-generated programs to capture neuroscientific datasets.
We have been applying this approach specifically to the problem of discovering computational models that capture animal learning behavior. The pipeline starts with a “prompt” containing an example program and instructions for the LLM on how it should be modified. The LLM proposes modifications, and each new program is scored on how well it fits behavioral data. On each iteration, the example programs in the prompt are replaced by the higher-scoring LLM-generated programs. The resulting programs fit data well, having been optimized for that purpose, and are relatively readable, having been generated by LLMs trained on human-written code. The hard part is then making sense of these models: understanding what different code elements do and how they relate to prior work.
This line of work illustrates a broader trade-off introduced by generative AI. Historically, constructing a model was the main challenge for theorists, with that process implicitly enforcing desirable properties such as grounding in prior literature, interpretability, novelty and focus on phenomena of interest. With generative tools, creation is easy, but quality is not guaranteed. The challenge for computational neuroscientists is now to explicitly formalize exactly what properties we want our models to have.