Dopamine neurons register surprise: Their activity surges when an experience exceeds expectations and falls silent with disappointment. These prediction errors help brains and artificial-intelligence systems learn from experience by updating future expectations, according to a long-standing model.
But because dopamine neurons receive input from several sources, the exact circuit mechanisms that compute the difference have remained mysterious, says Naoshige Uchida, professor of molecular and cellular biology at Harvard University.
It turns out that a circuit of just two types of neurons is central to this computation. Dopamine neurons in the ventral tegmental area calculate the error based on input originating from D1 medium spiny neurons in the striatum, according to unpublished mouse data Uchida and his team presented at this year’s Computational and Systems Neuroscience (COSYNE) annual meeting and reported in a preprint posted on bioRxiv in October 2025.
This result suggests that “reward learning doesn’t necessarily involve higher-order computation,” says Kauê Costa, assistant professor of psychology at the University of Alabama at Birmingham, who was not involved in the work. “The canonical view is that these types of computations would involve higher-order areas.”
But it also bolsters the reward prediction error model, which has come under scrutiny in recent years, says Nathaniel Daw, professor of computational and theoretical neuroscience at Princeton University, who was not involved in the study. “It’s amazing” how much explanatory power the model has had in predicting neuronal responses, he adds. “It’s been a long road to get here. It’s a really beautiful study.”
N
atural rewards activate many parts of the brain besides the main dopamine network in the ventral tegmental area, making it difficult to isolate specific circuits related to dopamine-dependent learning. To avoid this issue, Uchida and his colleagues created an artificial reward-learning paradigm. Instead of training mice to expect a water reward whenever they smelled a particular odor, the team paired the odor with optogenetic stimulation of dopamine neuron axons in the nucleus accumbens, a part of the striatum implicated in reward learning.Over time, the activity of D1 medium spiny neurons in these mice increased in response to odors that predicted reward, which is typically the case in classically trained mice. These neurons and the dopamine neurons therefore form the “minimal loop” required to compute prediction errors, Uchida says.
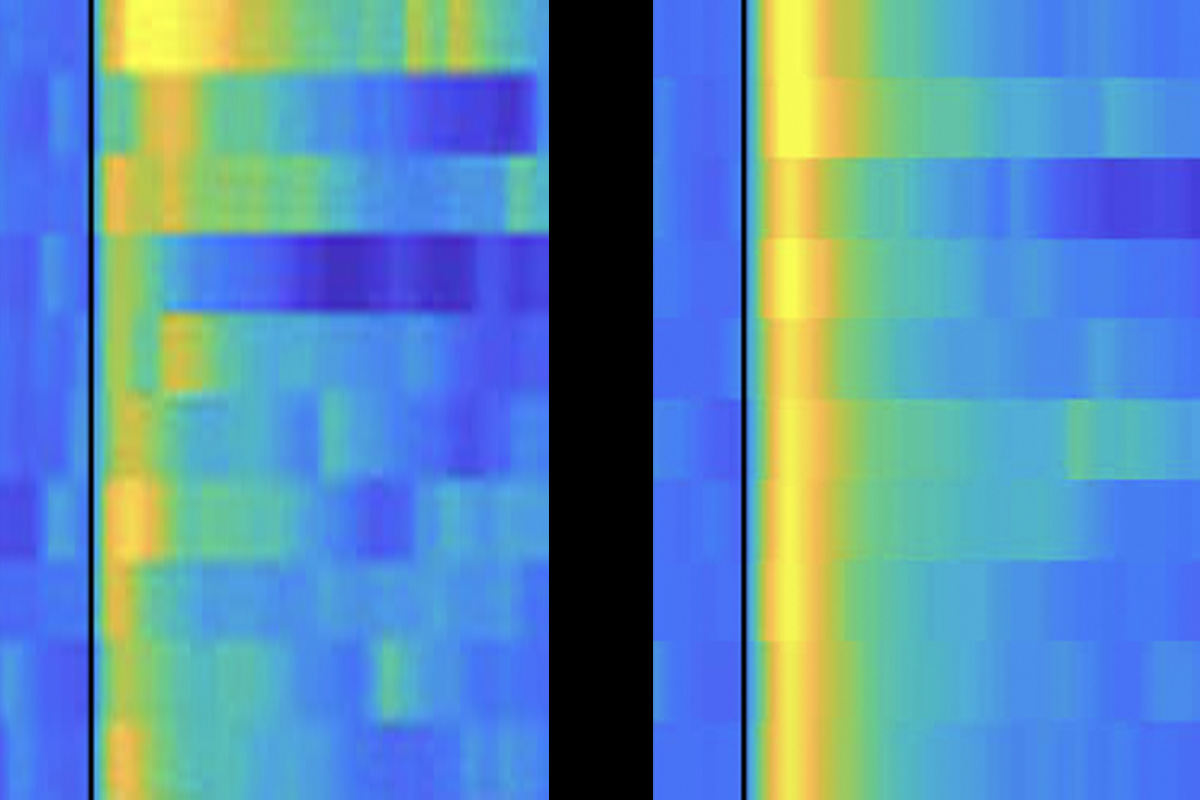
Optogenetically stimulating the cell bodies of D1 medium spiny neurons in the nucleus accumbens drove a burst of activity in dopamine neurons, followed by delayed inhibition. Because the inhibition arrives just after the burst, the dopamine neurons effectively subtract what just happened from what is currently happening, thereby approximately computing what is known as a temporal-difference signal.
“That was really unexpected,” Uchida says. “The neurons we’re stimulating are inhibitory, and they’re directly connected to dopamine neurons. But it matches perfectly with the idea that input from the striatum gets transformed into a TD error.” Temporal difference (TD) error, a type of reward prediction error, is the mathematical signal that drives temporal difference learning, a machine-learning algorithm that continually compares expected and actual rewards and that accurately predicts dopamine neuron responses.
Dopamine neurons in naive animals that hadn’t received odor conditioning or optogenetic stimulation also showed TD-error-like responses when they received patterned input from D1 medium spiny neurons. This observation suggests that the ability to compute TD error is built into the circuit even before any learning takes place, Uchida says.
The timing of these responses may also explain why immediate rewards are more compelling than delayed ones, a phenomenon known as temporal discounting. The relative magnitudes of excitatory and inhibitory inputs in this circuit may effectively set how long an animal is willing to wait for a future reward, leading to individual differences in impulsivity, the findings suggest.
TD error is only part of learning, however, Uchida says. “Reward learning is supported by other, different mechanisms. We are not claiming that all reward learning is totally dependent on TD learning or even dopamine.”
I
ndeed, the new findings do not “totally rule out” an alternative model of reward learning called adjusted net contingency for causal relations (ANCCR), says Vijay Mohan K. Namboodiri, associate professor of neurology at the University of California, San Francisco, who proposed the ANCCR model. According to ANCCR, dopamine neurons signal whether a current, meaningful event is causally related to a recent one, which also involves calculating the difference in value of the current state and the previous state.The new study is valuable, though, because it shows that “the circuit basis for this [temporal difference] computation involves the D1 MSNs [medium spiny neurons] within the lateral nucleus accumbens and the dopamine neurons,” Namboodiri adds.
How the brain determines a reward’s value in the first place is still unclear, Daw says. And there’s also a question of where the dopamine neuron’s error signals travel and how different areas use it, he adds.
Moreover, it isn’t entirely clear how applicable the findings will be to mice behaving in naturalistic settings, Costa says. The researchers looked at changes in facial expressions after odor conditioning, but showing that optogenetic stimulation actually alters choices would strengthen their claim that the D1 medium spiny neuron-dopamine neuron circuit is the minimum circuit required to calculate TD error, Costa says. Although the researchers did manage to carefully isolate the circuit, he adds, the mice were still awake, indicating that other brain regions could still be at play.
Uchida says that TD error isn’t the complete story of how the brain learns from rewards and that other areas are likely involved in reward-based learning. Still, he says, TD error “is an important part of the big picture.”