LISTEN TO THIS STORY:
0:00
/
The “Brainhack” hackathon revealed that disagreement in neuroscience runs deeper than most researchers suspect—even in electrophysiology, a field that prides itself on hard data.
If you ask multiple teams of skilled neuroscientists to detect hippocampal ripples in the same brain recordings, you might expect them to converge on an answer. Unfortunately, you would be wrong.
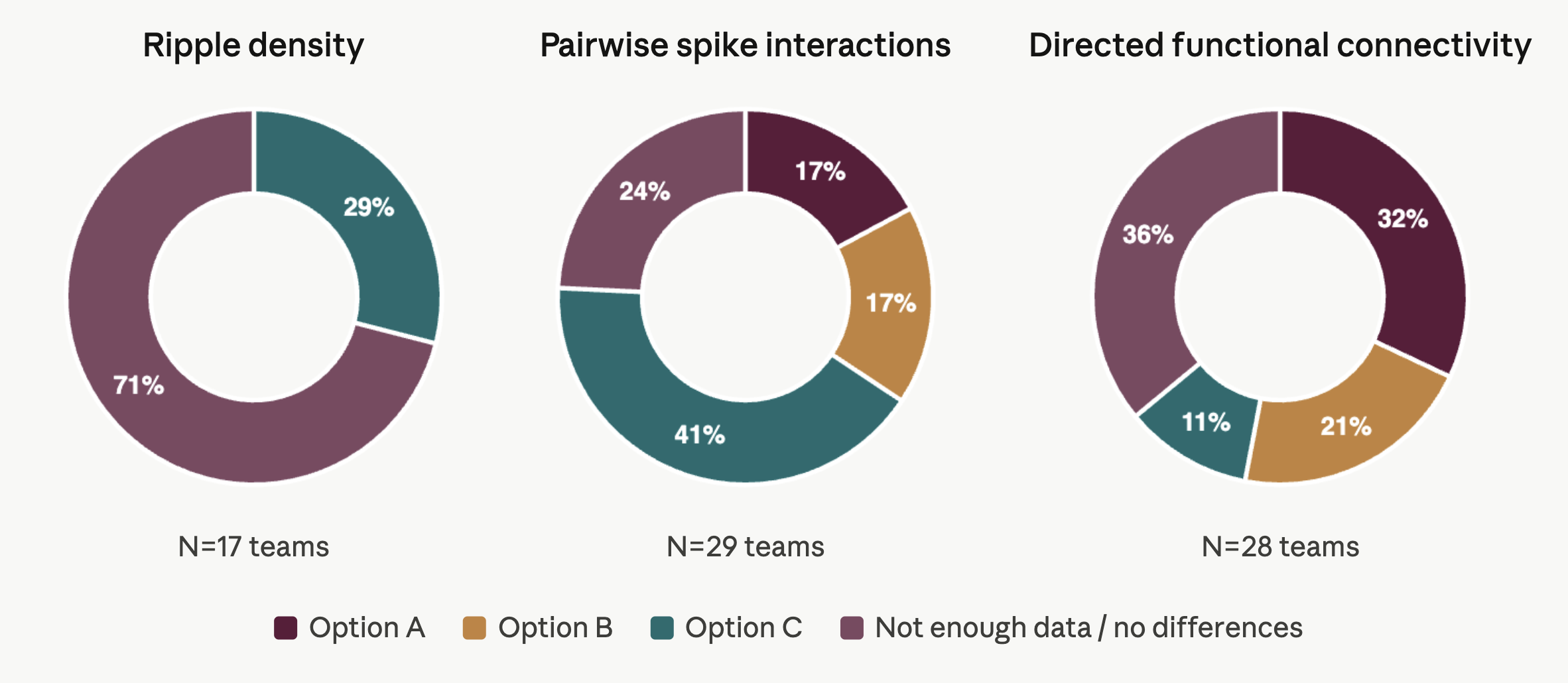
At “Brainhack,” a hackathon we organized at the Champalimaud Foundation in March, 18 teams analyzed identical Neuropixels datasets to determine which brain area, if any, had the highest density of sharp-wave ripples. On the surface, they appeared to reach a consensus: 12 out of 17 of the teams reported no differences in ripple density across three anonymized brain areas. But this agreement was largely superficial. The shared conclusion—“no difference”—emerged from fundamentally different observations, ranging from detecting virtually no ripples at all to identifying up to 10 ripples per minute in each region.
The teams had all deployed reasonable methods: Some followed an approach proposed by a recent consensus paper on ripple identification, some used deep-learning-based detectors, and others relied on classical bandpass-and-threshold techniques with varying parameters. Yet these defensible choices led to radically different absolute estimates, revealing that the apparent consensus masked a wide divergence in what the teams actually saw in the data. The results were so divergent that one has to wonder: If we cannot agree on how to define a ripple, what else might we be getting wrong?
To help shine more light on these issues, we have launched a collaborative project called CON²PHYS (CONceptual CONsistency in electroPHYSiology), which aims to quantify how much disagreement exists when neuroscientists interpret fundamental concepts. If our preliminary results are any indication, the project stands to say something consequential about how systems neuroscience is actually practiced.
T
he analytical variability problem in neuroscience is not new. In 2020, Rotem Botvinik-Nezer and her colleagues published a landmark study in Nature in which 70 independent teams analyzed the same functional MRI dataset. No two teams chose the same workflow, and the resulting variation in conclusions was substantial. That study sent shock waves through the brain-imaging community.Electrophysiologists, by contrast, have often taken confidence in the apparent clarity of their measurements. Spikes are discrete and countable: You either record an action potential or you do not. There is no need to model hemodynamic responses, contend with imaging artifacts or rely on complex statistical corrections. But results from the March hackathon suggest that we should reconsider this perspective.
Brainhack brought together roughly 40 researchers working in teams of 2 or 3. Each team received the same anonymized dataset of single-unit activity and local field potentials from three simultaneously recorded brain areas across 18 mice. The organizers asked participants to answer four multiple-choice questions, which were deliberately underspecified—for example, “Which brain area pair has the strongest directed functional connectivity?”—mirroring the ambiguity that researchers navigate every day.
The responses to three of the questions were not encouraging. The sharp-wave ripple question, which produced such divergent results, was supposed to be the most concrete. Questions concerning directed functional connectivity—a measure of how well the activity of one brain area predicts the activity of another—and spike-spike interactions, a measure of how often two spike trains co-occur above chance, produced even more divergent answers. Teams split their responses nearly evenly across all available options. Notably, the findings almost perfectly replicate the outcome from a similar hackathon held at the Bernstein Conference in 2025. Across two events and more than 100 researchers, these questions have yet to produce a discernible consensus.
Not everything was equally divisive. The fourth question, on neural decoding, produced substantially more agreement at both events, likely because classification accuracy is a well-defined scalar that most approaches roughly converge on, regardless of how they get there. This matters because it shows that the disagreement we observe is not a generic property of the protocol.
So what drove the divergent results? Lack of skill likely isn’t the issue; the hackathon participants were experienced researchers, many of whom work with this kind of data daily. Differences emerged on multiple fronts, including how researchers defined the concepts in question; the algorithms they used to analyze the data; and the parameters they set when implementing the algorithms. For example, some teams defined a ripple primarily by applying envelope thresholds on filtered signals; others required co-occurrence with a sharp-wave deflection in the local field potential; and some relied on visual heuristics based on their experience. These are not the same thing, and the specific definition determined which events were detected.
E
ven more concerning is the fact that researchers at the hackathon had no incentive to find any particular answer. They were not defending a hypothesis, advancing a narrative or trying to publish a result. They were simply analyzing data and reporting their results, yet they still found massive disagreement. Now consider what happens in the real world of academic publishing. Every one of these analytical choices is a “researcher degree of freedom.”In a context where careers depend on novel, significant findings, the same flexibility that produced innocent disagreement at a hackathon has far greater consequences. A researcher who needs a small p-value to complete a story may be swayed by an analytical pipeline that delivers it, without ever leaving the bounds of what the field considers methodologically acceptable. This is not fraud. It is the ordinary, unremarkable consequence of too many defensible choices and too little transparency about which ones were made and why. There is no need to fabricate data when the analysis does it for you.
Future hackathons can help us better understand the scope of the problem. A third is planned as a satellite event at the FENS Forum in July 2026. (This and previous hackathons were organized with support from the International Brain Laboratory and sponsored by the Wellcome Trust and the Simons Foundation, The Transmitter’s parent organization.)
In addition, the full CON²PHYS project is now open for participation, with a submission deadline of 30 November 2026. Any neuroscientist with relevant experience can download the dataset and answer the 15 multiple-choice questions, spanning topics from firing rates to neural dimensionality. We plan to publish a paper on the results and include any researcher who makes a significant contribution as co-author. If you have ever looked at a paper and wondered whether the results would have looked different had someone else run the analysis, this is your chance to find out.
In the longer term, CON²PHYS aims to develop practical, nonprescriptive tools to make conceptual uncertainty visible and quantifiable. These tools could take several forms: wider adoption of reference analytical pipelines that provide a shared starting point for the most fragile concepts; machine-readable reporting standards that make explicit what was actually computed under a given label; and sensitivity tools that enable researchers to load their own data and see, in real time, how their results change as they vary the algorithmic and parameter choices that are typically made once and never revisited.
Perhaps most importantly, the field may need to internalize a simple principle: If a methodological choice is arbitrary, the conclusions that rest on it should be shown to be insensitive to it. A finding that is “true” should be robust to analytical alternatives. The goal is not to impose a single correct answer where the science is genuinely open; rather, it is to make the consequences of arbitrary choices impossible to ignore.